
Abstract:
本文记录C++的基础知识及一部分C++11、C++17特性。
基础概念
内存分区
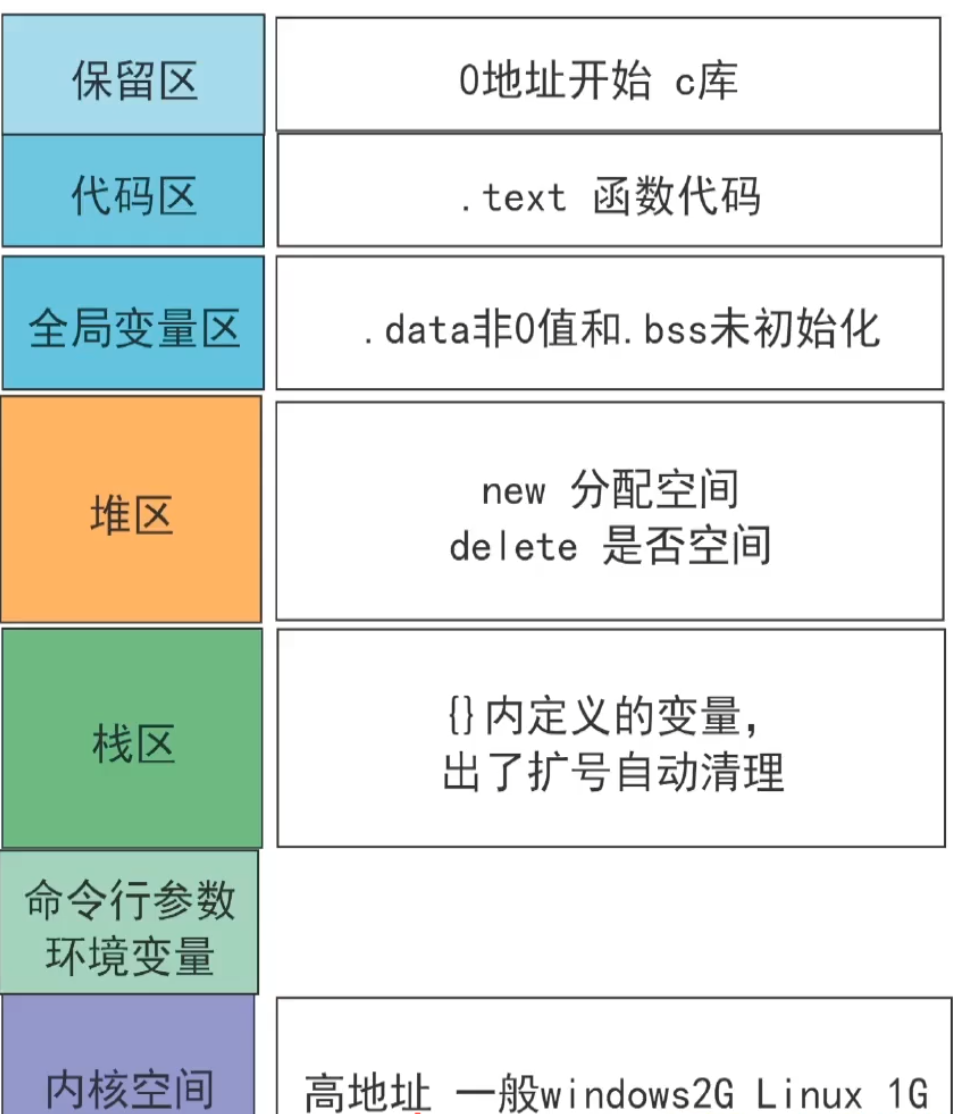
程序运行前
代码区:只读、共享(多个相同程序运行一段代码)
全局区:全局变量、静态变量、常量(字符串常量、
const修饰的全局变量)全局区分为3部分:
.data和.bss:全局变量、静态变量声明时未初始化或初始为0时,保存在.bss,否则在.data。- 常量区:保存
const修饰的全局变量,以及字符串字面量。
运行时
堆区和栈区不占用进程地址空间。
- 栈区:由系统管理,保存局部变量、局部常量、函数参数值。
连续的内存的区域。系统提供相关指令,效率更高。 - 堆区:程序员管理,结束时系统回收。堆是
不连续的内存区域,获得的空间比较灵活,也比较大,一般速度比较慢,容易产生内存碎片。由语言提供相关指令,效率更低。
创建在栈上的变量在未初始化时,其内存中会使用
cc填充。- 栈区:由系统管理,保存局部变量、局部常量、函数参数值。
运算符等
运算符
==
如果比较的是引用型对象,则比较两者地址,如string应该用a.compare(b)比较是否相等
#
在宏定义中表示拼接字符,如L###funcname表示L#funcname
#define toString(a) #a
#define link(a,b) a##b
int a = 0, ab = 1;
cout << toString(a); // a
cout << link(a,b); // 1
&&
右值引用:非 const 右值引用只能操作右值
A(const A&&); //移动构造函数使用右值引用
&
取址:int* a = &b;
引用:int&a = b;
指针和引用的区别
- 引用不可以为null
- 引用不可以更改其指向对象
- 引用创建时便初始化
sizeof引用”得到的是所指向的变量(对象)的大小,而“sizeof指针”得到的是指针本身的大小;- 指针和引用的自增(++)运算意义不一样;
- 引用是类型安全的,而指针不是
本质:就是指针常量const int* const
常量引用
const int &a = 10;
//编译器会自动修改为
int tmp = 10;
const int &a = tmp;
int &a = 10; // 报错,因为10不在内存中
->
重载:
class E{ public: void Print(){}; };
class ScopePtr{
public: E *p;
E* operator->() const { return p; }
};
ScopePtr p;
p->Print();
获取成员在类中的偏移:
class A { public: float a, b, c; };
int offset1 = (int)&((A*)nullptr)->a; //0
int offset2 = (int)&((A*)nullptr)->b; //4
int offset3 = (int)&((A*)nullptr)->c; //8
A* tmp = (A*)nullptr; // 0x00000000
float* tmp2 = &(tmp->b); // 0x00000004
int tmp3 = (int)tmp2; // 4
关键字
const
可以修饰普通变量,也可以修饰类的成员。不能修饰类外的函数。
const int a[n];
const vector<int> a(n); // vector的长度和内容不变,与上一行等价
常量指针和指针常量
const int const *a; //等价于const int*,常量指针
int* const a; //指针常量
const int* const a;//指向常量的指针常量
const *int a;//非法,*前面必须是类型名
修饰成员函数时与常引用搭配:
class A{ public: int x; int GetX() const { return x; } };
void func(const A& a){ int x = a.GetX(); } // 可行,因为GetX保证不会修改a。
class A{ public: int x; int GetX() { return x; } };
void func(const A& a){ int x = a.GetX(); } // 报错,因为GetX可能会修改a。
注意:
const修饰成员函数时,只限制类的成员,类外的变量可以修改,也可调用类外的函数。const修饰成员函数时,如果返回的类型是引用,则返回类型也要有const修饰。const不能和static同时修饰成员函数
class A{ static RendererAPI GetAPI() const {} }; //报错
typedef
定义别名
typedef int a[10]; // a 是一个包含10个int的数组的别名
typedef void* (*GLADloadproc)(const char *name);
typedef void* (*)(const char *name) GLADloadproc;
//GLADloadproc是指向一个返回void*,参数为const char *name的函数指针
delete
delete释放堆上的内存时
- 将对应内存的值设为随机值(而栈上的变量离开作用域释放时不会修改值,栈指针只是简单的移动)
- 指针指向的地址不变
static
static在c++14后用于单例时是线程安全的,不需要额外加锁。
在类或结构体外:表示变量或函数仅在当前翻译单元可见
类或结构体内:表示类实例共享成员。父类的static成员和子类继承的对应的static成员是同一份。
class A { private: static int x; }; class B :public A { }; int B::x = 1; //可以通过子类的域解析初始化父类的static成员函数作用域内的static变量:第一次进入函数时创建该变量,之后不会再创建,并一直存在直到程序结束。但是仅在该作用域内可以访问。
static成员函数不能同时用virtual、const、volatile修饰class A{ static RendererAPI GetAPI() const {} }; //报错
枚举类
enum class Type:char{ A, B }; //底层类型和enum一样只能是整形int、char等
与enum的区别:
- 枚举中的名称只在
Type作用域下,无法直接通过枚举中的名字访问。如只能为Type::A.而enum可以直接用A访问,导致与其他同名的变量或函数冲突。 - 枚举类对象不可以与整形隐式地互相转换。而
enum可以。
基本类型
字符串
字符串字面量:
const char* c = "test"; const wchar_t* c2 = L"test"; const char16_t* c3 = u"test"; const char32_t* c4 = U"test";char:每个字符占1字节,“test”保存在常量段中的内容为'test', 00H,其中00H表示\0。wchar_t:每个字符占2字节,常量段中的内容为't', 00H, 'e', 00H, 's', 00H, 't', 00H, 00H, 00Hchar16_t:每个字符占2字节,和wchar_t相同,如果两者内容相同则指向同一地址的字面量char32_t:每个字符占4字节,常量段中的内容为't', 00H, 00H, 00H, 'e', 00H, 00H, 00H, 's', 00H, 00H, 00H, 't', 00H, 00H, 00H, 00H, 00H, 00H, 00H
作用:由于不同编译器可能
char和wchar的大小不同,所以可以通过char16和char32指定。定义字符串时如果使用字面量拼接,中间不要
+,否则报错:const char* c = "line1" "line2";'line1line2', 00H
类型转换
static_cast
c风格的类型转换,与一般的隐式转换和显示转换所做的相同。
不能用于指针类型的转换。
reinterpret_cast
类型双关。只对指针有效,即将指针所指内存中的内容解释为目标类型。
int x = 1;
double x2 = static_cast<double>(x); // x2 = 1.0000
double x3 = *(reinterpret_cast<double*>(&x)); // -4.5917540251594387e-30
dynamic_cast
用于继承关系间的转换,只能用于包含虚函数表的类。如果一个父类指针实际指向目标子类,则可将该指针转换为子类指针,否则返回空指针。
原理:使用RTTI(Run Time Type Info)记录类型信息,增加了开销。如果在VS设置中关闭RTTI,再使用dynamic_cast则会因为无法访问RTTI而报错。
2.4.4、const_cast
只作用于指针。可以通过指针形式修改常量。
const int x = 1;
int* px = const_cast<int*> (&x);
(*px) = 2; // x = 2
指针和数组
指针数组和数组指针
int *p[10]; //指针数组
int (*p)[10]; //数组指针
(int *)p[10]; //强制类型转换
智能指针
头文件:<memory>
智能指针主要是为了防止堆资源分配后忘记释放导致内存泄露。
void UseRawPointer(){
// Using a raw pointer -- not recommended.
Song* pSong = new Song(L"Nothing on You", L"Bruno Mars");
// Use pSong...
// Don't forget to delete!
delete pSong;
}
void UseSmartPointer(){
// Declare a smart pointer on stack and pass it the raw pointer.
unique_ptr<Song> song2(new Song(L"Nothing on You", L"Bruno Mars"));
// Use song2...
wstring s = song2->duration_;
//...
} // song2 is deleted automatically here.
Efficient17:始终在单独的代码行上创建智能指针,而绝不在
参数列表中创建智能指针,这样就不会由于某些参数列表分配规则而发生轻微泄露资源的情况。
智能指针类型:
unique_ptr4字节,仅有
一个实例拥有内存所有权,用于不能被多个实例共享的内存管理。可以通过move(unique_ptr)作为右值传递给函数参数,如果函数参数是左值常量,则可以直接传递。std::unique_ptr<Fraction> f1{ new Fraction{ 3, 5 } }; std::unique_ptr<Fraction> f2; // 初始化为nullptr f2 = f1 // 非法,不允许左值赋值 f2 = std::move(f1); // 此时f1转移到f2,f1变为nullptr // 也可以用 std::unique_ptr<Resource> res void takeOwnerShip(std::unique_ptr<Resource>&& res){} auto ptr = std::make_unique<Resource>(); takeOwnerShip(ptr); // 非法 takeOwnerShip(std::move(ptr)); // 必须传递右值 // 左值常量 void useResource(const std::unique_ptr<Resource>& res){} useResource(ptr);shared_ptrshared_ptr与unique_ptr的主要区别在于前者是使用引用计数的智能指针。当最后一个引用对象离开其作用域时,才会释放这块内存。主要用于多线程。和
weak_ptr有共同的父类,继承的是父类中的控制块,包括引用计数、弱引用计数等,自身的成员是一个指针。注意:
shared_ptr不能用于管理C语言风格的动态数组。不要使用同一块内存初始化多个
shared_ptr,而是通过拷贝赋值。Resource* res = new Resource; shared_ptr<Resource> ptr1{ res }; cout << ptr1.use_count() << endl; // output: 1 { // 用同一块内存初始化 std::shared_ptr<Resource> ptr2{ res }; cout << ptr1.use_count() << endl; // output: 1 cout << ptr2.use_count() << endl; // output: 1 } // 此时ptr2对象析构了, output:Resource destroyed cout << ptr1.use_count() << endl; // output: 1 //最终会崩溃,因为通过相同内存初始化的两个指针没有通信,不知道对方的存在,同一块内存会被释放两次shared_ptr有可能出现内存无法被释放的情况,出现类似死锁的循环引用。class Person{ public: Person(const string& name): m_name(name){} friend bool partnerUp(std::shared_ptr<Person>& p1, std::shared_ptr<Person>& p2){ if (!p1 || !p2) return false; p1->m_partner = p2; p2->m_partner = p1; } private: string m_name; std::shared_ptr<Person> m_partner; }; { auto p1 = std::make_shared<Person>("Lucy"); auto p2 = std::make_shared<Person>("Ricky"); partnerUp(p1, p2); // 互相设为伙伴 }//最终由于引用不能归0,无法释放导致泄露。weak_ptr用于解决
shared_ptr的循环引用。weak_ptr可以包含由shared_ptr所管理的内存的引用。但是它仅仅是旁观者,并不是所有者。weak_ptr不拥有这块内存,不会计数,也不会阻止shared_ptr释放其内存。但是它可以通过lock()方法返回一个shared_ptr对象,从而访问这块内存。class Person{ public: ...... private: string m_name; std::weak_ptr<Person> m_partner; }; { auto p1 = std::make_shared<Person>("Lucy"); auto p2 = std::make_shared<Person>("Ricky"); partnerUp(p1, p2); // 互相设为伙伴 }//可以释放weak_ptr<A> p = make_shared<A>(); //需要由shared_ptr初始化。
函数
参数
参数默认值
声明和实现只能有一个有默认值。
占位参数
只有类型没有名字,调用时必须传,可以有默认值。
可变参数列表函数
#include <stdarg.h>
void func(int argNum, ...){
va_list args;
va_start(args, argNum); //通过argNum确定参数个数
while(argNum--){
int arg = va_arg(args, int); //int确定参数类型
}
}
可变参数模板
void myPrint(){}
template <class T, class... Args>
void myPrint(T fisrtArg, Args... args){
cout << fisrtArg << endl;
myPrint(args...); // 逐层剥离参数,所以需要一个无参的myPrint()
}
template <class T>
void myPrint(initializer_list<T> args){
for(auto arg:args){
cout << arg << endl;
}
}
函数调用过程
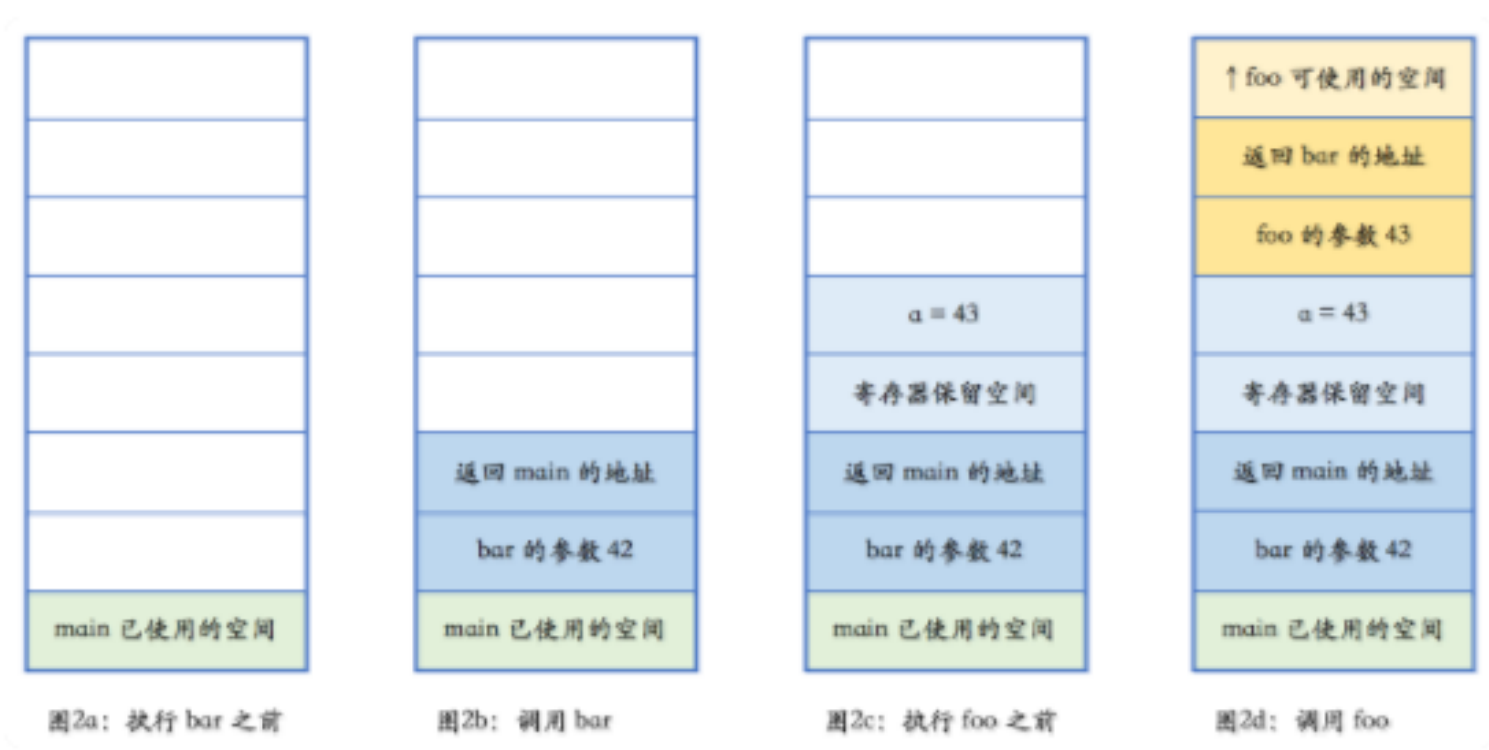
void foo(int n){}
void bar(int n){ int a = n+1; foo(a); }
int main(){ bar(42); }
- 先将参数压如栈中
- 把下一行代码的指令地址作为返回地址压如栈中
- 把当前寄存器的内容压如栈中
- 栈帧:图中每种颜色代表一个栈帧,是分配给函数使用的空间,共三个栈帧
类和对象
三大特性
- 封装:
- 将属性和行为作为一个整体
- 权限控制
- 继承
- 多态
成员
成员变量
静态成员变量
定义:类内声明,类外定义和初始化。在编译阶段分配内存,存放在全局区。类对象共享。
const static(同static const)成员变量class A{ public: static int a; static const int b = 10; //可以在类的定义体中初始化 A(){ cout<< "create A."<<endl; } ~A(){ cout<< "delete A."<<endl; } A(const A&){ cout<< "copy A."<<endl; } }; int A::a = 1; const int A::b;//定义仍在外面 //在类中设置初始值后,如果外部没有定义会无法访问其地址,但仍可通过对象访问值。访问:通过类名或对象名访问。
成员对象
先调用成员对象的构造,析构时则相反
成员函数
声明和定义:
如果类内声明的同时给出实现,则为
内联。内联以空间换时间,避免了函数调用的一系列开销。但如果函数体内花费的时间比调用开销大,则不宜用内联。如果类内声明类外实现则不是内联,但可以在
实现处用关键字inline转为内联调用方式:调用类的方法使用::,调用对象方法使用.或->
默认提供:无参构造、析构、拷贝
如果定义了有参构造则不会提供默认构造,但会提供拷贝构造
如果提供了拷贝构造,则不再提供默认的无参、拷贝。
静态成员函数
static静态成员函数只能调用静态成员函数和静态成员变量。且静态成员函数不能声明为const,virtual,volatile。访问:同静态成员变量,通过对象或类名。因为静态函数无法区分调用该方法的对象,所以不能访问非静态成员变量/函数。
构造函数
无参构造函数
有参构造
拷贝构造函数
如果有
指针或动态内存分配,则必须给出拷贝构造函数避免析构时同一内存多次释放。通过
=用相同对象赋值时会自动调用拷贝构造。移动构造函数c++11(http://c.biancheng.net/view/7847.html)
作用:
避免深拷贝时由于大空间拷贝导致的效率降低。
以移动而非深拷贝的方式初始化含有指针成员的类对象。将其他对象(通常是临时对象)拥有的内存资源“移为已用”。
引入了右值引用的语法,实现移动语义。 注意:
- 使用临时对象初始化当前类的对象,优先调用移动构造函数。
- 左值初始化调用拷贝构造,右值初始化调用移动构造
std::move()函数,可以将左值强制转换成对应的右值,由此便可以使用移动构造函数。
调用:
调用时机:
相同类对象赋值;
值传递作为参数;
值方式返回局部对象。调用方法
- 括号法
A a; //无参 A a(args); //有参 A a = arg; //隐式转换 //拷贝构造 A a; A a2(a); 注:使用
explicit修饰一个参数的构造函数,防止隐式类型转换- 显示法
A a = A(); //无参 A a = A(args); //有参 A(args); //右侧A(args)单独在一行则称为匿名对象,匿名对象创建后立刻执行析构释放 //拷贝构造 A b; A a = A(b);注:
- A a();会被认为是函数声明,因此不能通过此方式调用默认构造函数。
- 不要利用拷贝构造函数初始化匿名对象
A a; A(a); // 报错,等价于A a,发生重定义
析构函数
初始化列表和构造函数的区别
初始化列表效率更高。当类中包含复杂对象时,初始化列表会少调用一次成员对象的构造函数,节省时间。class E{ public: E(){ cout << "create" << endl; } }; class A{ public: E e; A(){ e = E(); } // 相当于先E e;调用一次默认构造,再e = E();调用一次默认构造。 A(): e(E()){} // e = E();调用一次构造。 A(): e(){} // E e();调用一次构造。 };
类和结构体
区别:
结构体成员默认是公有的,类成员默认是私有的
结构体只能包含成员变量,而类可以包含函数,结构体也可以使用函数指针实现结构体函数
c++对象模型和this指针
成员变量和成员函数分开存储
类的成员变量和成员函数分开存储。
只有非静态成员变量才属于类的对象。
空对象占用空间为1字节,为了区分内存中的空对象。
class A{
public:
int mA; // 非静态成员变量占对象空间
static int mB; //不占对象空间
void func(){} //也不占对象空间,所有函数共享一个函数实例
};
this指针
每个成员函数只有一份函数实例,多个同类型对象共用这一段代码。
问题:这块函数代码如何区分那个对象调用自己?
答案:通过特殊的对象指针this。
this指向被调用的成员函数所属的对象。
this指针不需要定义,直接使用。
本质:指针常量,指向不可修改。存放在寄存器中,对象调用时对自身取址传入该参数。
用途:
形参和成员变量重名时用this区分。
类的非静态成员函数中返回对象本身。
class A{ public: //返回引用&,否则会调用拷贝构造 产生匿名对象 //返回引用的好处是可以链式调用 //如:a.func().func().func(); A& func(){ return *this; } //也可以使用*,但不能链式调用 A* func(){ return this; } };
空指针访问成员函数
空指针也可以调用成员函数,但如果函数内用到this指针(如成员变量的访问)则会报错。
class A{
public:
int m_a;
void func(){}
void func2(){ cout<<m_a;}
};
A* p = nullptr;
p->func();//正确
p->func2();//出错
const修饰成员函数
常函数:
- 成员函数后加
const为常函数void func() const{} - 常函数内不可以修改成员属性
- 成员属性声明时加
mutable后,则在常函数或常对象中可以修改。 - 常函数只能调用常函数
常对象:
- 声明对象前加
const 常对象只能调用常函数
友元
让一个函数或类可以访问当前类的私有成员
三种实现:
- 全局函数做友元
- 类做友元
- 成员函数做友元
void func(A *a);
class A;
class B{
void funcB(A *a);
};
class A{
friend void func(A *a);//全局函数做友元
friend class B;//类做友元
friend void B::funcB(A *a);//成员函数做友元
};
友元关系与继承
- 友元关系不可传递,即A是B友元,C是A友元,则C不是B友元。
- A的友元类B,C是B的子类,则C不是A的友元。
- A的友元类B,C是A的子类,则B不是C的友元,但B可以访问C中继承的A的私有成员。
运算符重载
包括成员函数重载和全局函数重载
运算法重载也可以发生函数重载
不能重载:::,?:,.,#,sizeof,.*,->*
/
//本质
A A::func(A& a){
A tmp;
tmp.x = this->x + a.x;
return A;
}
//使用成员函数重载,相当于替换函数名
A A::operator+(A& a){...}
A a3 = a1.operator+(a2); // 简化后:A a3 = a1 + a2;
//全局函数重载
A operator+(A &a1, A &a2);
A a3 = operator+(a1, a2);// 简化后:A a3 = a1 + a2;
<<
//成员函数重载
void operator<<(cout);
// 简化后是 a << cout,顺序不对, 且无法链式调用,所以要全局重载
//全局重载
ostream& operator<<(ostream &out, A &a){
out << a.x;
return out;
}
cout << a << endl;
//然后使用friend将该重载声明为友元,以输出私有成员
–
//前置
A& operator++(){
++x;
return *this;
}
//后置,使用占位参数区分前后置,注意只能用int编译器才能识别
A operator++(int){
A tmp = *this;//先保存
++x;
//返回值,因为使用的临时变量,不能返回引用
//因此后置不能链式
return tmp;
}
=
//重载=和重载默认拷贝构造是一样的,如果重载了默认拷贝构造,则=会调用
//该拷贝构造
A& operator=(A &a){
//先释放已有堆区
if(x != nullptr){
delete x;
x = nullptr;
}
x = new int(*a.x);//深拷贝
return *this;
}
关系运算符
bool operator==(A &a){}
函数调用运算符()
class A{
void operator()(string s); //很像函数调用,所以叫仿函数
};
A a;
a("Hello");
匿名函数对象
A()("Hello");
继承
继承方式
公共继承
保护继承
私有继承
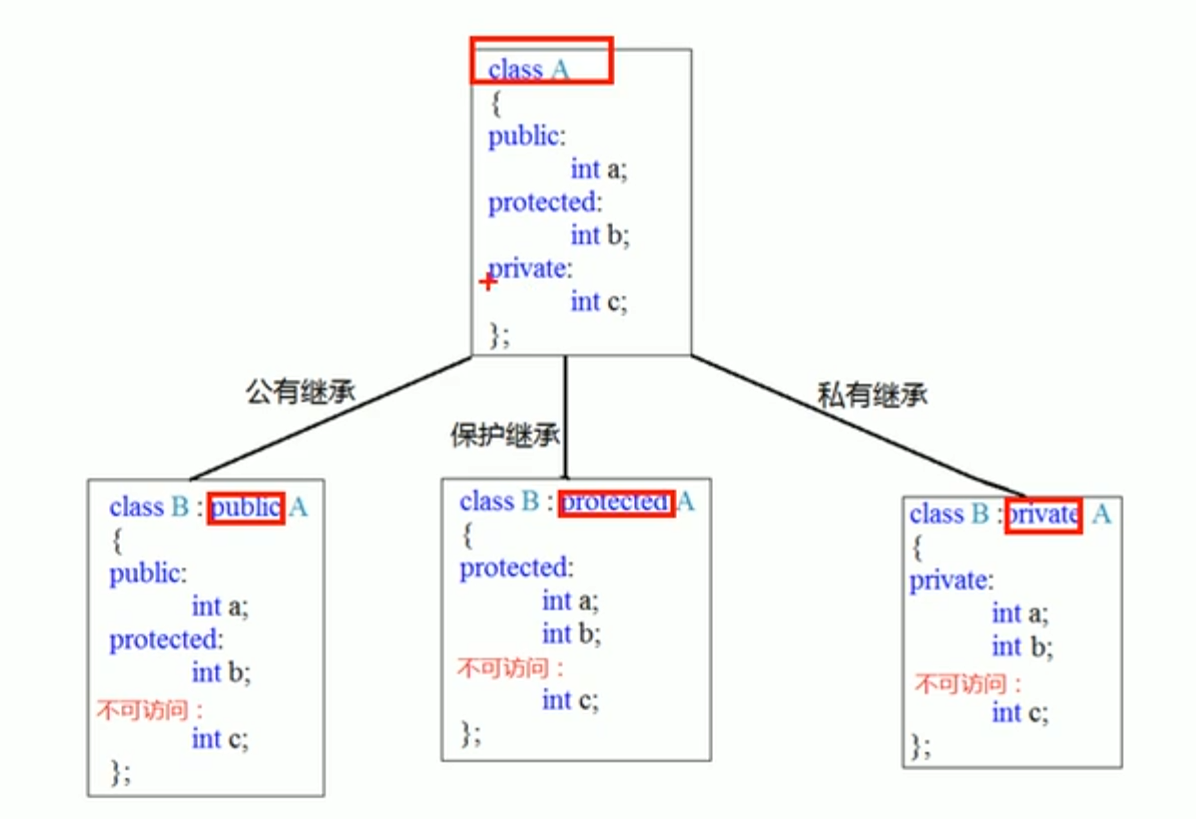
继承中的对象模型
从父类继承过来的成员,哪些在子类对象中?
使用VS的开发人员命令工具查看对象模型,在文件目录中键入cl /d1 reportSingleClassLayout类名 cpp文件名
继承中同名成员
class Base{
public:
void func();
void func(int a);
};
class Derive: public Base{
public:
void func();
};
Derive d;
子类同名成员直接访问。
父类同名成员需要加作用域。
d.func();//调用子类
d.Base::func();//父类
遮蔽(掩蔽)
d.func(1);//报错,因为子类有同名函数,则遮蔽父类中所有同名函数
d.Base::func(1);//成功
继承中同名静态成员
通过对象名访问静态成员与5.7.3相同。
通过类名访问:
Derive::x;
//第一个::代表通过类名,第二个::代表通过作用域
Derive::Base::x;
注意:继承过来的静态成员和父类中的静态成员地址是一个。
多继承语法
语法:class 子类: 继承方式 A, 继承方式 B{};
不建议使用多继承。因为不同父类可能有同名成员,此时需要使用作用域访问。
菱形集成
概念:又叫钻石继承,两个派生类B,C继承同一个类A,而又有一个类D同时继承这B,C。
问题:
- 同名成员二义。可以使用作用域解决。
- 两个父类继承了两份祖父成员,造成存储空间浪费。使用
虚继承解决。

使用虚继承后:
class B: virtual public A{};
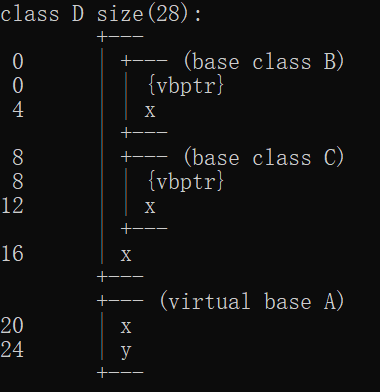
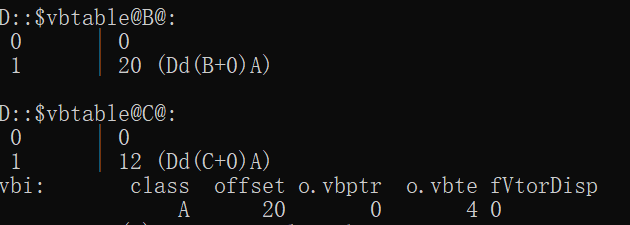
vbptr指向对应的vbtable。
如B的vbptr指向D::$vbtable@B@,然后通过在指针的地址0上加上保存的偏移量20得到虚基类的起始地址。
访问虚基类的属性:通过子类直接访问。
多态
静态多态:函数重载、运算符重载
动态多态:派生类、虚函数实现运行时多态
区别
静态多态函数地址早绑定 - 编译阶段确定函数地址
//编译阶段绑定 class Animal{ public: void speak(); }; class Cat: public Animal{ public: void speak(); }; void doSpeak(Animal &animal){ animal.speak(); } Cat cat; doSpeak(cat); // 调用的是animal的speak动态多态函数地址晚绑定 - 运行阶段确定函数地址
//运行阶段绑定 class Animal{ public: virtual void speak(); }; Cat cat; doSpeak(cat); // 调用的是cat的speak动态多态满足条件:
- 有继承关系
- 子类要
重写父类虚函数(重写:函数的返回值、函数名、参数完全相同)
动态多态使用:父类的
指针或引用指向子类对象。
动态多态原理
类中声明虚函数后,类的大小将会增加4字节(多个虚函数也是一样),即一个虚函数表指针vfptr。vfptr指向vftable。
vftable内部记录虚函数的地址。
如果子类没有重写父类虚函数,则子类会继承父类的vfptr和vftable。
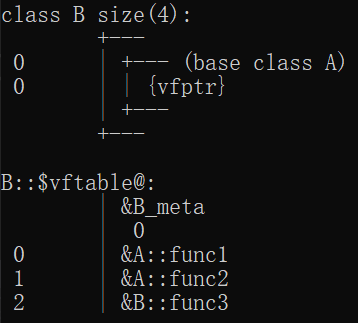
如果重写虚函数:子类继承vftable后会将对应的虚函数地址替换成子类重写的函数的地址。
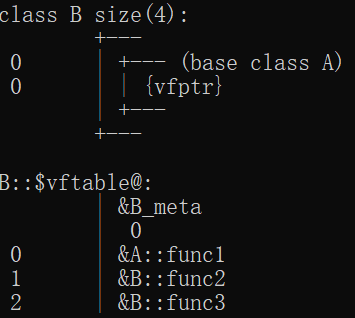
子类对象使用::可以调用基类的虚函数实现。
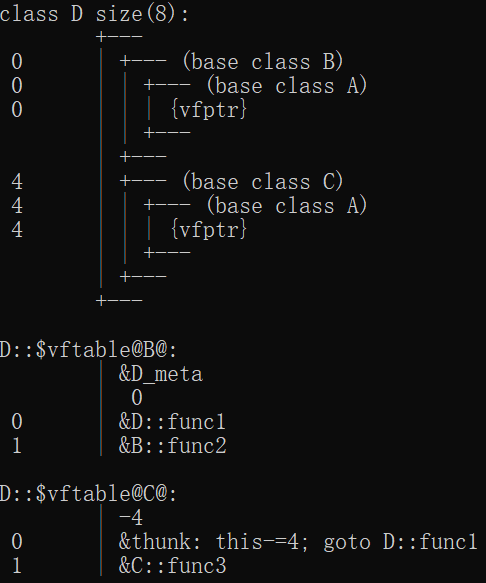
多继承下的虚函数:
- B、C、D均不使用虚继承。
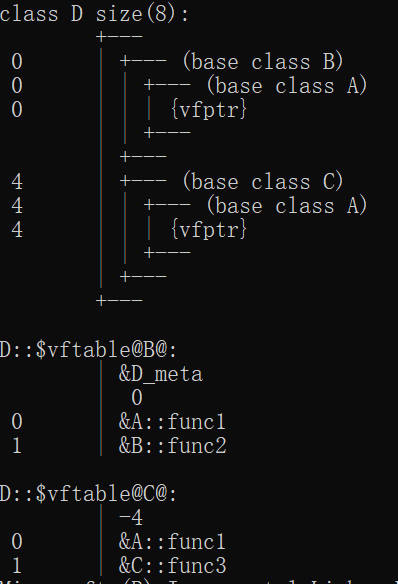
D有两个虚函数表,分别从B和C继承过来。此时如果在D中重写A的虚函数则会修改两张表。
B、C使用虚继承:
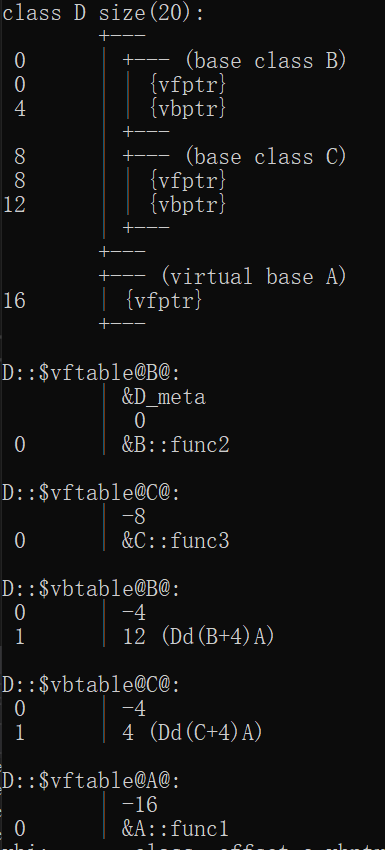
D会存在A、B、C的三个虚函数表,这是由于B、C是虚继承,所以当B、C也声明虚函数后,会重新创建一个虚函数表。
B、C虚继承,D重写A中的虚函数
func1: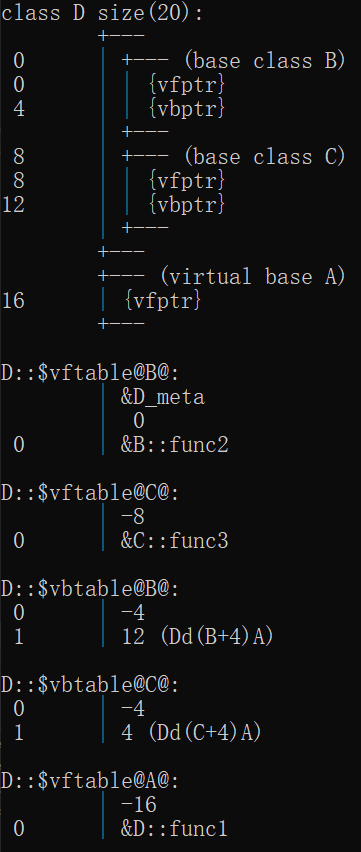
纯虚函数和抽象类
在多态中,通常父类中的虚函数实现是毫无意义的,主要都是调用子类重写的内容,因此可以将虚函数改为纯虚函数。
抽象类:包含纯虚函数的类。
- 无法实例化对象
- 子类必须重写纯虚函数,否则也属于抽象类
虚析构和纯虚析构
问题:多态使用时,父类指针在delete时无法调用子类的析构代码,导致子类属性开辟的堆内存无法释放。
解决:父类中的析构函数变为虚析构函数。在父析构函数前添加virtual。
纯虚析构:包含纯虚析构的类也是抽象类
class A{
public:
virtual ~A() = 0;
};
A::~A(){}//父类的纯虚析构也需要有实现以释放父类中开辟的堆内存。
文件操作
通过文件将数据持久化
头文件:<fstream>
文件类型:
- 文本文件:以文本的
ASCII码形式存储 - 二进制文件:以
二进制形式存储,一般不能直接读懂。
操作:
ofstream:写操作Ifstream:读操作fstream:读写操作
文本文件
写文件
步骤:
- 创建流对象:
ofstream ofs; - 打卡文件:
ofs.open("文件路径", 打开方式); - 写数据:
ofs<<"写入的数据"; - 关闭文件:
ofs.close();
| 打开方式 | 解释 |
|---|---|
ios::in |
为读文件而打开 |
ios::out |
为写文件而打开 |
ios::ate |
初始位置:文件尾 |
ios::app |
追加方式写文件 |
ios::trunc |
如果文件存在先删除,再创建 |
ios::binary |
二进制方式操作 |
注意:可以通过"|"组合使用。
设计模式
单例模式
懒汉式(线程安全+自动回收)
- 将实例声明为
静态的私有成员,保证在程序运行中不会因为作用域自动回收 - 默认构造函数声明为
私有,禁用拷贝构造和移动构造,保证不会有其他创建对象的路径 - 声明一个
内部私有类Garbo,在其析构函数中回收单例内部分配的空间。 - 在公有的
静态成员函数getInstance中,创建对象和回收类的静态对象,以在程序结束时,通过静态对象的释放,自动回收单例中的空间。
class SingletonLazy{
private:
static T* instance;
static pthread_mutex_t mutex;
// 自动回收单例
class Garbo{
public:
~Garbo(){
cout << "Garbo Start" << endl;
if(instance != nullptr){
delete instance;
instance = nullptr;
}
cout << "Garbo End" << endl;
}
};
protected:
SingletonLazy() { cout << "create SingletonLazy" << endl; };
// 析构为protected, 防止通过此基类操作子类时无法释放子类内存而导致内存泄露, 如果为private则子类无法调用父类析构导致出错
~SingletonLazy() {cout << "delete SingletonLazy" << endl; };
public:
static T* getInstance();
// 禁用move构造
SingletonLazy(T&&) = delete;
// 禁用copy构造
SingletonLazy(const T&) = delete;
};
template <typename T, bool isThreadSafe>
T* SingletonLazy<T, isThreadSafe>::instance = nullptr;
template <typename T, bool isThreadSafe>
pthread_mutex_t SingletonLazy<T, isThreadSafe>::mutex = PTHREAD_MUTEX_INITIALIZER;
template <typename T, bool isThreadSafe>
T *SingletonLazy<T, isThreadSafe>::getInstance() {
if(isThreadSafe){
if (instance == nullptr) {
pthread_mutex_lock(&mutex);
static Garbo garbo; // 初始化垃圾回收
if (instance == nullptr) {
instance = new T();
}
pthread_mutex_unlock(&mutex);
}
}else{
if (instance == nullptr) {
instance = new T();
}
}
return instance;
}
}
使用方法:
class A: public SingletonLazy<A>{
//声明模板为友元,方便调用构造函数A()
friend class SingletonLazy<A>;
private:
A(){ printf("create A.\n"); }
public:
~A(){ printf("delete A.\n"); }
A(const A&) = delete;
A(const A&&) = delete;
};
7.1.2、饿汉式
模板
模板不可以直接使用。模板只有在真正调用时,编译器才会将其转换成对应类型的代码然后编译。
- 函数模板
- 类模板
函数模板
8.1.1、语法
typename可以用class代替
template <typename T>
T func(){}
使用方式:自动推导类型、显示指定类型。
func(a,b);
func<int>(a,b);
8.1.2、注意
- 自动推导时,必须推导处一致的数据类型T才可以使用
- 模板必须确定出T的数据类型才可以使用
8.1.3、与普通函数的区别
- 自动推导时不能隐式类型转换
- 显示指定时可以隐式类型转换
8.1.4、调用规则
普通函数与函数模板同名时
如果两者都可以实现,优先调用普通函数,如果普通函数只有声明则会报错。
通过空模板参数列表强制调用函数模板
函数模板也可以重载
如果函数模板可以产生更好的匹配则调用函数模板
void func(int a){} template <typename T> void func(T a){} char c = 'a'; func(c);//调用函数模板
8.1.5、局限性
有些特定的数据类型需要用具体的方式特殊实现。
template<typename T>
void func(T &t){};
//对具体的A的实现
template<> void func(A &a){};
类模板
可以实例化对象
与函数模板区别
类模板没有自动类型推导
类模板的模板参数列表中可以有默认参数
template <class T, class T2 = int> class A{ public: A(T &a, T2 &b){}; }; A<string>(s, 10);//第二个模板参数取默认值int
成员函数创建时机
普通类成员函数一开始就可以创建
类模板的成员函数在调用时才创建
类模板对象做函数参数
传入方式
指定传入的类型(最常用)
template <class T1, class T2> class A{}; void func(A<string, int> &a){};参数模板化
template <class T1, class T2> void func(A<T1, T2> &a){};整个类模板化
template <class T> void func(T &a){};
类模板与继承
- 子类继承类模板时,要在声明时指定父类中T的类型
- 如果不指定,编译器无法给子类分配内存
c++11
原始字面量
语法:R"xxx(原始字符串)xxx",前后的xxx如果有则必须相同。
如字符串“H\t”拥有两种解释:三个字符:H、\、t或两个字符H、\t。
在c++11之前均采用第二种,c++11中可以通过定义原始字符串字面量输出第一种。
// 不使用原始字面量要使用转义字符 \
string str = "D:\\hello\\world\\test.txt";
// 字符串过长要使用 \
string str1 = "toolong1 \
toolong2";
c++11后:
string str = R"(D:\hello\world\test.txt)";
string str1 = R"(toolong1
toolong2)";
nullptr
NULL在C中定义为(void*)0,在C++中定义为0,因为c++不允许void*隐式转换为其他类型指针。
因此NULL和0在编译器看来是无法区分的,这在函数重载中会引起麻烦:
void func(char *p){};
void func(int p){};
char *p = NULL;
func(p); // 会调用func(int p),导致意料之外的错误
c++11后:nullptr可以进行自动转换。
constexpr
const两种语义:变量只读、修饰常量。
const int a = 10; //常量
int arr[a]; // 可行
void func(const int p){//变量只读
int arr[p]; //出错
}
constexpr修饰常量表达式,告知编译器,表示编译阶段即可得到其结果,可以进行替换以提高程序效率。
修饰
自定义类型constexpr struct T{ int a; }; //定义时不可用 constexpr T t{10}; //可行修饰函数返回值
constexpr int func(){} // 函数体内不能包含if、for等控制结构修饰
函数模板返回值时,最后会根据返回值确定是否为常量表达式。修饰
构造函数时,函数体必须为空,要在初始化列表进行初始化。
类型推导
auto
使用auto必须要对变量初始化。
如果变量不是指针或引用,则其const和volatile关键字不会保留。
int a = 1;
const auto b = a; // auto = int
auto c = b; // auto = int, != const int
const auto& d = a; // auto = int, d = const int&
auto& e = d; // auto = const int
auto e2 = d; // auto = int
const auto* d = &a; // d: const int*
const auto d2 = &a; // d2: int* const
限制
不能作为形参
不能用于类非静态成员初始化。因为非静态成员只有在对象创建时才能推导。
不能使用auto定义数组
ina arr[] = {1,2}; auto p = arr; // 可以 auto p2[] = {1,2}; // 不可以不能作为模板参数
decltype
推导时不用初始化,直接通过表达式推导。
int a = 1;
decltype(a) b = 99; // b:int
const int& y = a;
decltype(y) b2 = a; // b2:const int&
推导函数返回类型
const int func(){}
decltype(func()) a = 0; // a: int,返回值是纯右值,省略const
const int& func(){}
decltype(func()) a = 0; // a: const int&
const int&& func(){}
decltype(func()) a = 0; // a: const int&&
const T func(){}
decltype(func()) a = 0; // a: const T
推导表达式左值,或用()包围,得到引用
const T obj;
decltype(obj.num) a = 0; // a:int
decltype((obj.num)) b = a; // b:const int&
int m = 0, n = 0;
decltype(n+m) c = 0; // c:int
decltype(n = n+m) d = 0; // d:int&
返回值类型后置
用函数模板时,如果返回值类型也是未定的
template <class R, class T, class U>
R func(T t, U u){ return t + u; }
// 调用时,返回值类型需要提前知道函数怎么转换,不符合使用逻辑
auto res = func<decltype(t+u), 1, 3.0); // res: double
//错误写法,t,u定义在后面,所以无法推导
template <class T, class U>
decltype(t+u) func(T t, U u){ return t + u; }
使用返回类型后置
template <class T, class U>
auto func(T t, U u) -> decltype(t+u){ return t + u; }
auto res = func(1, 3.0); // res: double
final与override
final
限制某个类不能被继承,或虚函数不能重写。
class A{
public: virtual void func(){};
};
class B: public A{
public: void func() final {}; //重写并禁止此类的子类重写
};
class C: public B{
public: void func(); //出错!!
};
class B final: public A{};//禁止B被继承,丁克
override
提高重写虚函数时的可读性。
class A{
public: virtual void func(){};
};
class B: public A{
public: void func() override {}; //重写
};
模板的优化
连续>的优化
c++11前两个>>会被认为是右移操作符,必须在中间加空格> >。
函数模板参数的默认值
c++11前类模板参数可以有默认值,而函数模板不能。
新构造函数
委托构造函数
类中不同构造函数有冗余代码时,通过委托构造调用同一个类中其他构造函数
class A{
public:
A(){}
A(int a):A(){} // 调用了A()
};
继承构造函数
子类中直接使用父类构造函数,即using的使用。
c++11前:
class A{
public:
int a;
A(){}
A(int a){}
};
class B: public A{
public:
B():A(){} // 仅仅调用父类构造,写起来还麻烦
B(int a):A(a){}
};
c++11:
class B: public A{
public:
using A::A; // 直接使用父类所有构造
};
列表初始化
c++11前仅有数组和结构体支持列表初始化。
c++11其他类型也可以列表初始化
class A{
public: A(int a){}
};
//初始化列表初始化
A a{1};
A a1 = {1};
int i = {1};
int i{1};
模板类std::initializer_list
函数:
begin()、end()、size()作用:接受任意个相同类型参数
void func(initializer_list<int> ls); func({1,2,3});
基于范围的for循环
for(declaration : expression){}
使用细节
如果要修改,需要使用&,否则只会修改拷贝值
for(auto &v : container){ v++; }只读遍历
for(const auto& v : container){}set容器默认只读,通过&无法修改。
范围for循环在第一次进入时确定边界,之后不再判定,因此如果循环时增删元素会出错。
lambda表达式
语法
[capture](params) opt -> ret {body;};
capture:捕获列表,捕获一定范围内变量[]:不捕捉外部变量
int a; [](){ int c = a; // 报错,无法使用外部变量 };[&]:按引用的方式使用所有外部变量,可以修改原变量[=]:按值拷贝的方式,且传递的值只读int a; [=](){ a++; // 报错,无法修改 };[=, &foo]:foo变量按引用方式,其他外部变量使用拷贝方式。[foo]或[&foo]:只捕捉foo变量[this]:捕获当前类的this指针
opt:选项,可以省略
mutable:可以修改值传递进来的拷贝,但还是不能修改本身
int a = 0; [=]()mutable{ a++; // a = 1 }();//加()调用该函数 // a = 0exception:指定函数抛出的异常
ret:返回值,省略时
->也要省略
自动推导返回值
auto f = [](int i){return i;}
右值引用
左值与右值
- 左值:locate value,可以定位,存储在内存,可
取地址 - 右值:read value,只能读取,
不能取地址
左值引用与右值引用
左值引用
int num = 0; int& a = num; const int& c = num; //常量左值引用右值引用
只能通过右值初始化
int&& a = 1; const int&& b = 1; const int&& b1 = a; //报错 auto&& b2 = num; // b2: int& 而不是int&& auto&& b3 = 1; // b3: int&&作用:延长临时对象的生命周期,避免拷贝导致效率低下。
移动构造函数
T(T&& t):p(t.p){ t.p = nullptr; //避免p指向的内存被释放 }调用时机:用临时对象赋值时,如果有移动构造函数则调用。如果没有则要求右侧是临时对象,左侧显示使用右值定义。
void func(){return T(); } //返回不能取地址的右值,T没有移动构造 T&& t = func(); // 显示定义+右值,此时复用了整个临时对象,不止p
move
将左值转为右值
将资源进行转移。减少拷贝次数。
将类的右值引用作为另一个类的构造参数时,如果用初始化列表赋值则需要使用move,否则会调用拷贝构造。
class B{ B(A&& a):(m_a(a)){} // copy B(A&& a):(m_a(std::move(a)){} // move }使用=和右值赋值,需要重载=
class A{ public: A& operator=(A&& a) { if(this == &a) return *this; // 如果是给自己赋值直接返回 delete[] m; // 先删除已有的内存,防止泄露 m = a.m; a.m = nullptr; return *this; }; }
forward(完美转发)
一个右值引用作为函数参数传入时,在函数内就变成了左值,并不是原本的类型了。此时如果要按照原本的类型转发到另一个函数,则可使用forward。
std::forward<T>(t);
如果T是左值引用,则t会转换成右值,否则转换的结果都是左值。?
用法实例:vector的emplace实现
template<typename... Args>
void emplace_back(Args&&... args){
m_Data[size] = T(std::forward<Args>(args)...); // 会调用拷贝或移动构造
new(&m_Data[size]) T(std::forward<Args>(args)...); //不会调用拷贝或移动构造
}
emplace
emplace与push的区别:
push会先构造临时对象,然后将临时对象拷贝到vector中;而emplace如果将构造函数的参数直接传入,则会直接调用对应构造函数在vector中构造对象,省去了拷贝。
emplace和push都借助完美转发,根据传入的参数是左值还是右值,决定使用拷贝构造还是移动构造。
class A{ public: A(){} A(const A& a){ cout<<"copy"<<endl; } A(A&& a){ cout<<"move"<<endl; } }; vector<A> vec; vec.reserve(10); // 保留空间,避免拷贝 A a; vec.emplace_back(); // 直接调用构造函数 vec.emplace_back(a); // 传入左值,调用copy vec.emplace_back(A()); // 传入右值,调用move vec.push_back(); // 出错 vec.push_back(a); // 传入左值,调用copy vec.push_back(A()); // 传入右值,调用move
可调用对象
定义
一个函数指针
int func(int a){}; int (*funcPtr)(int) = &finc;一个重载
operator()的类的对象(仿函数)struct A{ void operator()(int a){}; }a; a(1);一个可以被转换成函数指针的类对象
using funcPtr = void(*)(string); struct A{ static void func(string s){ cout << s << endl; } operator funcPtr(){ return func; } // 只能是static,因为非static函数还有一个隐含的this指针参数会导致类型不匹配 }a; a("ss");一个类成员的指针
struct A{ void func(int a){}; int m; }a, a2; void (*funcPtr)(int) = A::func;//出错,因为func有隐含参数this void (A::*funcPtr)(int) = &A::func; //类成员函数指针,不能省略域解析符A::,因为A::func是指向类成员的指针,而指向类成员(非static)的指针并非指针, void (A::*funcPtr)(int) = A::func; //等价 int A::*m = &A::m; //类成员变量指针 (a.*funcPtr)(1); //调用成员函数 a.*m = 100; //初始化对象的成员变量 a2.*m = 50; //初始化对象的成员变量 cout << a.m <<","<< a2.m << endl; //100,50
包装器
类的成员函数指针不能直接用包装器包装,还需要绑定器。
#include <functional>
std::function<返回类型(参数类型列表)> diy_name = 可调用对象;
包装普通函数
function<void(int)> funPtr = func;包装类的静态函数
function<void(int)> funPtr = A::func;包装转换成函数指针的对象或仿函数
A a; function<void(int)> funPtr = a;
作用:通过将包装器类型作为函数参数,可以方便的将函数名作为函数参数传递。
void print(int a){};
void callback(const function<void(int)>&func){ func(1); }
callback(print);
绑定器
作用
- 将可调用对象 和对应参数绑定在一起成为仿函数
- 减少参数:将多参数可调用对象转为更少参数的可调用对象
//非类成员
auto f = std::bind(可调用对象地址,绑定的参数/占位符);
//类成员
auto f = std::bind(类成员地址,类对象地址,绑定的参数/占位符);
占位符:placeholders::_1:这个位置将在函数调用时被传入的第一个参数替代
void func(int x, int y){}
bind(func, 1, 2)();//固定参数为1、2,绑定后调用即func(1,2);
bind(func, placeholders::_1, 2)(10); //func(10, 2);
bind(func, 2, placeholders::_1)(10); //func(2, 10);
bind(func, 2, placeholders::_2)(10); //出错,调用时没有第二个参数
bind(func, 2, placeholders::_2)(10,20);//func(2, 20);
//func(10,20)
bind(func, placeholders::_1, placeholders::_2)(10,20);
//绑定类成员
class A{
public: void func(int x, int y){}
int m;
};
A a;
auto f1 = bind(&A::func, &a, 5, placeholders::_1);
function<void(int, int)> f11 = f1; //隐式转换成包装器类型
f1(10); // a.func(5, 10);
f11(20,20); // a.func(5, 20);
auto f2 = bind(&A::m, &a);
function<int&(void)> f22 = f2; //&保证可修改变量中的值
f2() = 666; //a.m = 666
f22() = 777;//a.m = 777
网络编程
socket是什么?套接字是什么? (biancheng.net)
基本概念
socket提供两种通信机制:
stream:流式传输,基于TCP,有序、可靠、双向字节流。datagram:数据报传输,基于UDP,不可靠,可能丢失和乱序。对数据长度有限制,效率高。音视频聊天可以采用。应用场景越来越少。
socket通信流程:

socket()
int socket(int af, int type, int protocol);//Linux
SOCKET socket(int af, int type, int protocol);//Windows
af:协议族(Address Family),即IP地址类型。也可以写作PF(Protocol Family),因此所有AF_XX等价于PF_XX。AF_INET:IPv4地址,如127.0.0.1。AF_INET6:IPv6地址,如1030::C9B4:FF12:48AA:1A2B。
type:数据传输方式,即socket类型。SOCK_STREAM:流式,基于TCPSOCK_DGRAM:数据报,基于UDP
protocol:传输协议。- 0:根据
af和type自动推导。当两种不同协议支持同一种af和type时,无法自动推导。 IPPROTO_TCP:TCP传输协议IPPROTO_UDP:UDP传输协议
- 0:根据
SOCKET sock = socket(AF_INET, SOCK_STREAM, 0);
bind()
将具体的地址和端口绑定到socket
注意绑定前要转为
网络字节序。
htons():host to network shorthtonl():host to network longntohl():network to host longntohs():network to host short
int bind(int sock, struct sockaddr *addr, socklen_t addrlen); //Linux
int bind(SOCKET sock, const struct sockaddr *addr, int addrlen); //Windows
sock:由socket()产生的socket描述符。addrlen:addr的大小,由sizeof计算。返回值:
addr:sockaddr结构体指针,将sockaddr_in转换得到struct sockaddr_in{ sa_family_t sin_family; //地址类型 uint16_t sin_port; //16位的端口号 struct in_addr sin_addr; //32位IP地址 char sin_zero[8]; //不使用,一般用0填充 };sin_family:和socket()的af取值一致。sin_port:端口号,取值范围为1024~65536,需要使用htons()进行转换。sin_addr:in_addr结构体。struct in_addr{ in_addr_t s_addr; //32位的IP地址,等价于unsigned long,是一个整数 }; //因为s_addr是一个整数,而IP地址一般是字符串,所以要使用inet_addr()进行转换 unsigned long ip = inet_addr("127.0.0.1");
为什么要转换为
sockaddr:
- 两者长度都是16B,只是
sockaddr将地址和端口合并到一起。要给sa_data赋值必须同时指定,如"127.0.0.1:80",但没有相关函数将字符串转成需要的形式,所以很难给sockaddr赋值,因此使用sockaddr_in代替。 sockaddr更通用,而sockaddr_in和sockaddr_in6分别保存IPv4和IPv6地址。
示例:
sockaddr_in sockAddr;
memset(&sockAddr, 0, sizeof(sockaddr_in)); //内存初始化为0
sockAddr.sin_family = AF_INET;
sockAddr.sin_port = htons(PORT);
sockAddr.sin_addr.S_un.S_addr = inet_addr("127.0.0.1");
bind(servSock, (sockaddr*)&servAddr, sizeof (servAddr));
connect()
int connect(int sock, struct sockaddr *serv_addr, socklen_t addrlen); //Linux
int connect(SOCKET sock, const struct sockaddr *serv_addr, int addrlen); //Windows
用来建立连接,参数和bind()相同,但connect()用于客户端。
listen()
使socket进入被动监听。即没有客户端请求时,socket处于“睡眠”,当接收到请求时,才会“唤醒”。
int listen(int sock, int backlog); //Linux
int listen(SOCKET sock, int backlog); //Windows
sock:进入监听的socketbacklog:请求队列的最大长度,如果为SOMAXCONN表示由系统决定,一般比较大。
请求队列
- socket正在处理客户端请求时,有新的请求进来,就将新请求放入缓冲区,即请求队列。
- 当请求队列满时,不再接受新请求,Linux的客户端会收到
ECONNREFUSED,Windows会收到WSAECONNRESFUSED。
accept()
listen()只是监听请求,accept()才真正接受并处理。accept会阻塞程序,直到有新的请求到来。
int accept(int sock, struct sockaddr *addr, socklen_t *addrlen); //Linux
SOCKET accept(SOCKET sock, struct sockaddr *addr, int *addrlen); //Window
sock:服务器端的socketaddr:保存客户端的IP地址和端口号- 返回值:一个新的socket,专门用来与该次请求的客户端通信
发送和接收数据
Linux下:
万物皆可为文件,因此socket和普通文件一样,可以直接使用write()/read()发送和接受数据
ssize_t write(int fd, const void *buf, size_t nbytes);fd:要写入的文件描述符,即socketbuf:要写入的数据的地址nbytes:要写入的字节数- 返回值:写入成功返回字节数,失败返回-1
ssize_t read(int fd, void *buf, size_t nbytes);fd:要读取的文件描述符,即socketbuf:存放读取出来的数据的地址nbytes:要读取的字节数- 返回值:读取成功返回字节数,如果读取到文件结尾返回0,失败返回-1
10.7.2、Windows
需要用专门的send()/recv()
int send(SOCKET sock, const char *buf, int len, int flags);- flags:发送数据时的选项。一般设置为0。
int recv(SOCKET sock, char *buf, int len, int flags);
socket缓冲区和阻塞模式
缓冲区
每个socket创建后都会有两个缓冲区,输入缓冲区和输出缓冲区。
write和send并不立即向网络中传输数据,而是先将数据写入输出缓冲区,再通过TCP协议将数据从缓冲区发送到目标机器。一旦数据写入缓冲区,函数就返回,不管发送。
read和recv同理。
缓冲区特性:
- 在每个TCP socket中单独存在
- 创建socket时自动生成
- 关闭socket后TCP仍会发送输出缓冲区的数据
- 关闭socket后输入缓冲区数据丢失
- 大小一般为8KB,通过
getsockopt获取 - 发送方在接收到ACK后才会清空输出缓冲区
阻塞模式
对于TCP socket,默认是阻塞的,也可以修改为非阻塞。
使用write和send发送数据时:
- 首先检查输出缓冲区,如果空间不够则阻塞,直到发送足够数据后空间足够才唤醒
- 如果TCP正在发送数据,阻塞write和send,直到发送完毕。
- 如果写入数据大于缓冲区,分批写入。
- 直到所有数据写入缓冲区,write和send才返回。
使用read和recv读取时:
- 首先检查输入缓冲区,如果有数据则读取,否则阻塞直到有数据
- 如果要读取的长度小于缓冲区中数据长度,则剩余数据会积压,直到再次读取。
- 直到读取到数据后才会返回,否则一直阻塞。
TCP的粘包(数据无边界性)
因为read时缓冲区数据可能是多次write的结果,所以无法区分每一次write的数据边界。例如两次分别写入1和3,读取时会读出13。
STL
vector
vector中存对象还是存指针?(尽量选择存对象)
- 如果存对象,由于内存连续,所以大概率在cache中的同一行,访问更快。但vector扩容时拷贝耗时更多。
- 如果存指针,则离散访问,cache命中率极低。但vector扩容时更快。
vector的使用优化
- 使用
reserve避免频繁扩容导致的拷贝操作。 - 使用
emplace代替push,直接在vector中构造对象,避免临时对象的创建和拷贝。
array
与vector的区别
array大小固定,也可以通过
size()获取长度。// 使用模板打印不同大小的array template <typename T> void PrintArray(const T& array) { cout << array.size() << endl; }array在栈上保存内容,vector则在堆上。
与普通的数组的区别
array可以打开边界检查,防止数组访问越界。
多线程
std::thread
使用std::thread创建一个子线程,构造参数为线程执行的函数指针
std::thread worker(DoWork);
join
阻塞当前线程并等待指定线程完成
static bool s_Finished = false;
void DoWork() {
while (!s_Finished) std::cout << "Working...\n";
}
int main() {
std::thread worker(DoWork);
std::cin.get();
s_Finished = true;
worker.join();
}
当前线程与线程休眠
std::this_thread获取当前线程
void DoWork() {
using namespace std::literals::chrono_literals;
std::cout << "Started thread id=" << std::this_thread::get_id() << std::endl;
while (!s_Finished) {
std::cout << "Working...\n";
std::this_thread::sleep_for(1s);
}
}
计时
c++11后可以使用标准库中的头文件chrono进行平台无关的计时操作。
using namespace std::literals::chrono_literals;
auto start = std::chrono::high_resolution_clock().now();
std::this_thread::sleep_for(1s);
auto end = std::chrono::high_resolution_clock().now();
std::chrono::duration<float> duration = end - start;
std::cout << duration.count() << "s\n";
利用作用域实现自动计时:
struct Timer {
std::chrono::steady_clock::time_point start, end;
std::chrono::duration<float> duration;
Timer() {
start = std::chrono::high_resolution_clock().now();
}
~Timer() {
end = std::chrono::high_resolution_clock().now();
duration = micro_end - micro_start;
float ms = duration.count() * 1000.0f;
std::cout << "Timer took " << ms << "ms\n";
}
};
void Func() {
Timer t;
for (int i = 0; i < 100; i++)
std::cout << "Hello\n";
}
benchmark(基准测试)
用chrono精准测试程序运行时间
~Timer() {
end = std::chrono::high_resolution_clock().now();
long long micro_start = std::chrono::time_point_cast
<std::chrono::microseconds>(start).time_since_epoch().count();
long long micro_end = std::chrono::time_point_cast
<std::chrono::microseconds>(end).time_since_epoch().count();
long long duration = micro_end - micro_start;
float ms = duration * 0.001f;
std::cout << "Timer took " << ms << "ms\n";
}
可视化计时
在chrome或edge的地址栏输入tracing,然后将指定格式的json文件拖入窗口即可。
生成json:
struct ProfilelResult {
std::string Name;
long long Start, End;
uint32_t ThreadId;
};
struct InstrumentationSession { std::string Name; };
class Instrumentor {
private:
InstrumentationSession* m_CurrentSession;
std::ofstream m_OutputStream;
int m_ProfileCount;
public:
Instrumentor() :m_CurrentSession(nullptr), m_ProfileCount(0) {}
void BeginSession(const std::string& name,
const std::string& path = "result.json"){
m_OutputStream.open(path);
WriteHeader();
m_CurrentSession = new InstrumentationSession{ name };
}
void EndSession(){
WriteFooter();
m_OutputStream.close();
delete m_CurrentSession;
m_CurrentSession = nullptr;
m_ProfileCount = 0;
}
void WriteProfile(const ProfilelResult& result){
if (m_ProfileCount++ > 0)
m_OutputStream << ",";
std::string name = result.Name;
std::replace(name.begin(), name.end(), '"', '\'');
m_OutputStream << "{";
m_OutputStream << "\"cat\":\"function\",";
m_OutputStream << "\"dur\":" << (result.End - result.Start) << ",";
m_OutputStream << "\"name\":\"" << name << "\",";
m_OutputStream << "\"ph\":\"X\",";
m_OutputStream << "\"pid\":" << result.ThreadId << ", ";
m_OutputStream << "\"tid\":0,";
m_OutputStream << "\"ts\":" << result.Start;
m_OutputStream << "}";
m_OutputStream.flush();
}
void WriteHeader(){
m_OutputStream << "{\"otherData\": {}, \"traceEvents\":[";
m_OutputStream.flush();
}
void WriteFooter(){
m_OutputStream << "]}";
m_OutputStream.flush();
}
static Instrumentor& Get(){
static Instrumentor* instance = new Instrumentor;
return *instance;
}
};
计时器在结束计时时写入内容:
class InstrumentationTimer {
public:
std::chrono::steady_clock::time_point m_StartTimepoint, end;
std::chrono::duration<float> duration;
InstrumentationTimer(const char* name) :m_Name(name), m_Stopped(false) {
m_StartTimepoint = std::chrono::high_resolution_clock().now();
}
~InstrumentationTimer() { if (!m_Stopped) Stop(); }
void Stop() {
auto endTimepoint = std::chrono::high_resolution_clock().now();
long long start = std::chrono::time_point_cast
<std::chrono::microseconds>(m_StartTimepoint).time_since_epoch().count();
long long end = std::chrono::time_point_cast
<std::chrono::microseconds>(endTimepoint).time_since_epoch().count();
std::cout << m_Name << ": " << (end - start) << "ms\n";
uint32_t threadId = std::hash<std::thread::id>{}(std::this_thread::get_id());
Instrumentor::Get().WriteProfile({ m_Name, start, end, threadId});
m_Stopped = true;
}
private:
const char* m_Name;
bool m_Stopped;
};
使用:
#define PROFILE_SCOPE(name) InstrumentationTimer timer##__LINE__(name)
#define PROFILE_FUNCTION() PROFILE_SCOPE(__FUNCSIG__)
void Function1() {
PROFILE_FUNCTION();
for (int i = 0; i < 1000; i++)
std::cout << "Hello World #" << i << std::endl;
}
void Function2() {
PROFILE_FUNCTION();
for (int i = 0; i < 1000; i++)
std::cout << "Hello World #" << sqrt(i) << std::endl;
}
void RunBenchmarks() {
PROFILE_FUNCTION();
std::cout << "Running Benchmarks...\n";
Function1();
Function2();
}
int main() {
Instrumentor::Get().BeginSession("Profile");
RunBenchmarks();
Instrumentor::Get().EndSession();
return 0;
}
async
头文件:<future>
异步执行指定函数。
std::async(std::launch::async, func);
- 第一个参数如果不是
async,则不一定会在不同线程执行。
std::vector<std::future<void>> futures; // 保存临时future结果,确保for循环中多线程执行
static std::mutex s_meshMutex;
static void LoadMesh(const std::vector<Mesh>* meshes, std::string path){
auto mesh = Mesh::Load(path);
std::lock_guard<std::mutex> lock(s_meshMutex);
meshes-push_back(mesh);
}
void LoadMeshes(){
for(std::string& path:paths){
futures.push_back(std::async(std::launch::async, LoadMesh, &meshes, path));
}
}
std::async为什么一定要返回值?
如果没有返回值,那么在一次for循环之后,临时对象会被析构,而析构函数中需要等待线程结束,所以就和顺序执行一样,一个个的等下去。如果将返回值赋值给外部变量,那么生存期就在for循环之外,那么对象不会被析构,也就不需要等待线程结束。
c++17
结构化绑定(tuple)
optional
用于处理可能存在的返回值。
std::optional<std::string> ReadFileAsString(const std::string& path) {
std::ifstream stream(path);
if (stream) {
std::string res;
// read
stream.close();
return res;
}
return {};
}
std::optional<std::string> data = ReadFileAsString("data.txt");
std::string res = data.value_or("failed.");//返回为空时为结果设置默认值“failed”。
if (data.has_value()) { // Success.
}
variant
存储多种类型的单一变量。
本质:创建类一个包含指定类型的结构体,因此大小是总和。
与union相比:类型安全,但更耗费空间。
std::variant<std::string, int> data;
data = "hello";
data.index(); // 0
data = 0;
data.index(); // 1
std::get_if<int>(&data);
any
存储任意类型.
原理:小类型使用union存放,大类型使用void*,动态分配内存。
std::any data;
data = 0;
data = "hello";
auto res = std::any_cast<const char*>(data);
面试问题
虚函数表存放在哪里?
虚函数表是存放在类中而不是对象中的。当生成类对象时,编译器将对象前四个字节设置为虚表地址,即vfptr。
由于类的虚函数在定义时就确定了,因此在编译阶段就可以确定虚函数表的内容,所以虚函数表存放在全局区的常量段。
虚函数可以是静态函数吗?
不可以。因为静态成员函数不需要传入this指针,所以不能通过this指针访问子类的vfptr,所以只会访问到父类的vfptr,也就无法实现多态。
类似的问题
静态成员函数不能为常函数:
static void fun() const {}因为一般的常函数通过将
this指针定义为const T*实现其效果,而静态成员函数没有this指针。
malloc和new的区别
malloc:void *malloc(unsigned int size)在
堆上申请连续空间,失败返回NULL,申请的内存不会初始化,会遗留之前程序的值calloc:void *calloc(unsigned int num, unsigned int size)在
堆上分配num*size大小的连续空间,并且将其中的值初始化为0realloc:void *realloc(void *ptr, unsigned int size)将
ptr指向的内存长度更改为size,如果比之前大,新增的数据不会初始化。如果ptr的连续空间不够,则重新找一块分配,然后拷贝值,并将ptr指向新的地址。不能用来操作栈上的空间。
alloca:在栈上申请内存,不会初始化。程序在出栈的时候,会自动释放内存。new:自动计算需要分配的空间,先调用malloc,再调用类的构造函数,对内存空间进行初始化placement_new:定位new,允许我们向 new 传递额外的参数指定内存分配的位置//buffer为全局变量则空间为全局区,局部变量则为栈区 char buffer[sizeof(T)]; T *p1 = new T; T *p2 = new(buffer) T;//此时分配的内存即buffer的内存 //delete p2; //不能用delete释放定位new的空间!! p2->~T(); //要调用析构函数释放